Research Topics
My research is on Responsible AI, Data Science, and Data Engineering. Here you may find my current research activities. A complete list of publications is here.
Algorithmic Fairness
Fairness of Recourse
We propose novel fairness definitions concerning algorithmic recourse. For an individual that receives an undesirable outcome (e.g., loan application rejected), recourse is a way to reverse the outcome (e.g., increase down payment). Recourse incurs a cost for the individual that can be measured quantitatively. Our definitions investigate whether subpopulations have comparable costs, i.e., bear the same burden, for recourse. We have developed a method, termed FACTS, to audit a model for fairness, i.e., find subgroups where unfairness exists.

Our approach is integrated within the IBM AIF 360 tool. See a demo notebook here.
Publication
Spatial Fairness
In many cases, it is important to ensure that a model does not discriminate against individuals on the basis of their location (place of origin, home address, etc.). We consider location as the protected attribute and we want the algorithm to exhibit spatial fairness For example, consider a model that predicts whether mortgage loan applications are accepted. Its decisions should not discriminate based on the home address of the applicant. This could be to avoid redlining, i.e., indirectly discriminating based on ethnicity/race due to strong correlations between the home address and certain ethnic/racial groups, or to avoid gentrification, e.g., when applications in a poor urban area are systematically rejected to attract wealthier people.
This work introduces PROMIS, a post-processing optimization framework designed to reduce spatial bias while maintaining predictive performance. Building on threshold-based equal opportunity adjustments and a robust definition of spatial fairness, PROMIS formulates an optimization problem that minimizes a normalized Spatial Bias Index (SBI), which quantifies expected spatial bias across regions. Unlike heuristic correction methods, PROMIS derives globally optimal, interpretable, and computationally efficient fairness adjustments through mathematical optimization, and, unlike white-box approaches, it can be applied to any classification model.

Publications
Fairness in Recommender Systems
In recommender systems, fairness may concern either the consumers (end users, buyers, etc.) that receive recommendations, or the providers (producers, sellers, etc.) of the items being recommended. We have developed a common method that post-processes recommendations so as to ensure either consumer or provider fairness.
When recommendations concern a group of people, rather than an invidivual, the system must also consider fairness within the group. That means each member of the group should receive roughly the same utility from the recommendations.
Publications
Model Explainability
Global Counterfactual Explainability
We propose a method for global explainability of black box models using counterfactual explanations. A counterfactual explanation locally explains an outcome by providing the minimal changes necessary to reverse the outcome, e.g., “if you had five more years of experience, your job application would have been accepted”. We develop a method, termed GLANCE, that summarizes all counterfactual explanations for a given model.

Solving this global version of counterfactual explainability is different than finding the local counterfatual explanations and picking among them.
Publication
Example-Based Explanations
For many use-cases, it is often important to explain the prediction of a black-box model by identifying the most influential training data samples. We propose AIDE, Antithetical, Intent-based, and Diverse Example-Based Explanations, an approach for providing antithetical (i.e., contrastive), intent-based, diverse explanations for opaque and complex models. AIDE distinguishes three types of explainability intents: interpreting a correct, investigating a wrong, and clarifying an ambiguous prediction. For each intent, AIDE selects an appropriate set of influential training samples that support or oppose the prediction either directly or by contrast. To provide a succinct summary, AIDE uses diversity-aware sampling to avoid redundancy and increase coverage of the training data.

Publication
Counterfactual Explanations for Recommendations
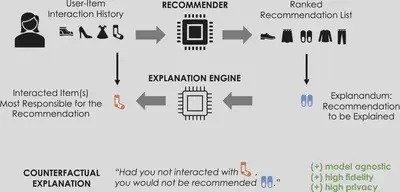
We develop a post-hoc, model-agnostic explanation mechanism for recommender systems. It returns counterfactual explanations defined as those minimal changes to the user’s interaction history that would result in the system not making the recommendation that is to be explained. Because counterfactuals achieve the desired output on the recommender itself, rather than a proxy, our explanation mechanism has the same fidelity as model-specific post-hoc explanations. Moreover, it is completely private, since no other information besides the user’s interaction history is required to extract counterfactuals. Finally, owing to their simplicity, counterfactuals are scrutable, as they present specific interactions from the user’s history, and potentially actionable.
Publication
Text Mining
Entity Extraction using Structured Data
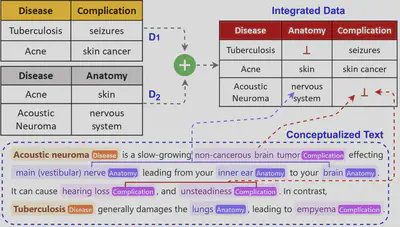
We propose THOR a novel method to extract information from text, that unlike related approaches, neither relies on complex rules nor models trained with large annotated corpus. Instead, THOR is lightweight and exploits integrated data and its schema without the need for human annotations. THOR significantly outperforms state-of-the-art Large Language Models in text conceptualization, particularly in entity recognition tasks, for data integration settings.
Publication
Record Linkage for Complex Records
We propose TokenJoin, a method for linking complex records, i.e., identifying similar pairs among a collection of complex records. A complex record is a set of simpler text entities, such as a set of addresses. To increase robustness, our approach is based on a relaxed match criterion, the fuzzy set similarity join, which calculates the similarity of two complex records based on maximum weighted bipartite matching instead of overlap.
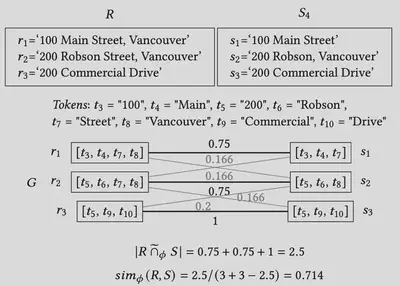
Publication
Data Intensive Pipelines
Cost-Aware Automated Machine Learning
Selecting an effective machine learning pipeline requires searching through many alternatives that differ in algorithms, hyperparameters, and data preparation steps. This complexity has led to the development of Automated Machine Learning (AutoML), which systematically explores pipeline configurations with minimal human input. However, AutoML is computationally expensive, often evaluating hundreds or thousands of pipelines per dataset, even though only a small fraction are ultimately selected for deployment.
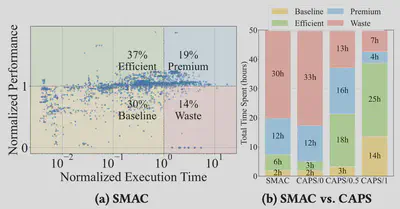
In an experiment using a popular AutoML with a five-hour budget per task, approximately 3,000 pipelines were evaluated based on classification accuracy and execution time. The results categorized pipelines into four groups: Baseline (low cost, low performance), Efficient (low cost, high performance), Premium (high cost, high performance), and Waste (high cost, low performance). Notably, about 14% of pipelines fell into the Waste category but consumed 60% of the total computational budget, highlighting substantial inefficiencies in the AutoML search process.
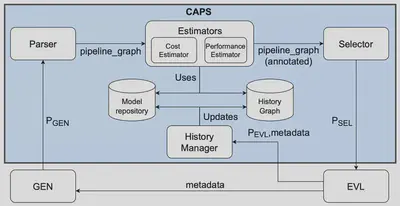
Cost-Aware ML Pipeline Selection (CAPS) enhances AutoML by introducing an intermediate selection step between pipeline generation and evaluation, enabling explicit prioritization based on a performance–cost trade-off. While the generation phase focuses on exploring diverse and promising candidates, the selection phase filters them according to desired cost efficiency, significantly reducing wasted computation and allowing more pipelines to be explored within the same budget. CAPS achieves this by estimating both predictive performance and execution cost at a fine-grained level, modeling the runtime of individual pipeline functions and leveraging execution-environment data from prior runs. This detailed cost modeling overcomes limitations of black-box approaches and accounts for system-level optimizations that can obscure true execution costs.
Publication
Optimizing Machine Learning Pipelines
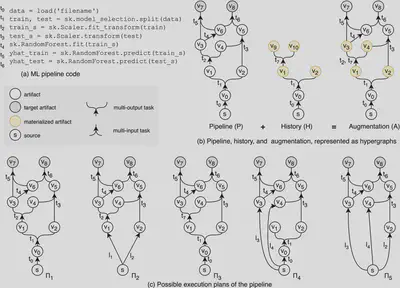
We propose HYPPO, a novel system to optimize pipelines encountered in exploratory machine learning. HYPPO exploits alternative computational paths of artifacts from past executions to derive better execution plans while reusing materialized artifacts. Adding alternative computations introduces new challenges for exploratory machine learning regarding workload representation, system architecture, and optimal execution plan generation. To this end, we present a novel workload representation based on directed hypergraphs, and we formulate the problem of discovering the optimal execution plan as a search problem over directed hypergraphs and that of selecting artifacts to materialize as an optimization problem.
Publication
Summarizing Streaming Big Data
When analyzing big data, it is often necessary to work with data synopses, approximate summaries of the data that come with guarantees. We propose a novel synopsis-as-a-service paradigm and design a Synopses Data Engine as a Service (SDEaaS) system, built on top of Apache Flink, that combines the virtues of parallel processing and stream summarization towards delivering interactive analytics at extreme scale.
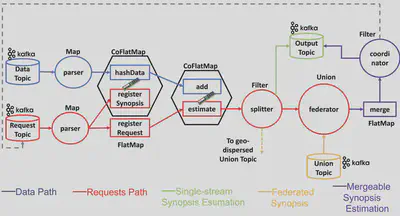
Publication