Type
Publication
ICDE 2024 - 40th International Conference on Extending Database Technology
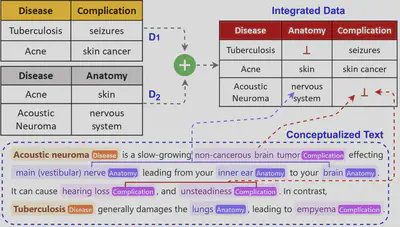
We propose THOR a novel method to extract information from text, that unlike related approaches, neither relies on complex rules nor models trained with large annotated corpus. Instead, THOR is lightweight and exploits integrated data and its schema without the need for human annotations. THOR significantly outperforms state-of-the-art Large Language Models in text conceptualization, particularly in entity recognition tasks, for data integration settings.